23. Contributi: Knowledge Retrieval per uscire dal caos *
di Luca Severini **
Tornate all'indice degli articoli
Tornate alla sala saggistica
Qualche anno fa incontrai un funzionario di un'organizzazione governativa che si occupa di sviluppo delle imprese, il quale mi sottopose il seguente problema.
L'attività del suo ufficio consisteva nel recuperare costantemente da Internet informazioni di svariata natura. Il metodo impiegato era quello di effettuare grandi ricerche con Google.
Poiché Google restituiva una quantità enorme di documenti, gli impiegati dell'ufficio spendevano gran parte del loro tempo a capire quali fossero i documenti che contenevano le informazioni desiderate.
In sostanza il funzionario si lamentava dell'efficacia di Google visto che gli impiegati dovevano leggere i documenti ad uno ad uno prima di capire se il documento fosse da scartare o da leggere.
Il suo desiderio era quello di capire se esistesse uno strumento dotato di capacità di discernimento in grado di selezionare automaticamente (ma forse è più corretto dire "magicamente") i documenti da far leggere agli impiegati.
Gli spiegai che a differenza di quanto lui immaginasse, non può esistere nessuno strumento in grado di risolvere quel problema in modo generale e per di più semplicemente. Ma vista la sua insistenza gli chiesi quale fosse il budget a disposizione per dotarsi di questo strumento. Mi disse che poteva mettere a disposizione qualche migliaio di euro e, indispettito dalla mia richiesta, fu sgarbato con me mettendo pesantemente in dubbio le mie affermazioni.
Congedandomi gli feci notare che il motore di ricerca Google, secondo lui così mediocre, è realizzato dalla compagnia più capitalizzata del mondo, che investe miliardi di dollari per mantenerlo aggiornato. E che non capivo come mai lui potesse pensare che per poche migliaia di euro qualcuno avrebbe mai potuto realizzare un sistema di ricerca migliore di Google!
Nei giorni successivi non potei fare a meno di ripensare a quell'episodio domandandomi come fosse stato possibile che una persona così poco preparata potesse essere a capo di un ufficio che per missione avrebbe dovuto aiutare le imprese. E come mai avesse potuto mettere in dubbio le competenze e le capacità di un imprenditore che rischia tutti i giorni in proprio, producendo reddito per sostenere se stesso e tutte le famiglie dei suoi dipendenti. Insomma, non mi sarei mai aspettato critiche da una persona che non rischia in prima persona e che preferisce il "posto sicuro" per esercitare un potere che non si merita.
Bruciato da quel fatto mi domandavo se in Germania o in Gran Bretagna i miei colleghi avessero mai potuto subire trattamenti poco riguardevoli e umilianti da parte di un funzionario dello stato il cui stipendio viene pagato proprio dai contribuenti.
Ovviamente non potevo spiegarmelo poiché nei paesi democratici i legittimi proprietari dello Stato sono i cittadini. E le istituzioni e i loro funzionari sono al servizio dei cittadini e delle imprese.
Ma forse nel nostro paese non è ancora così. Forse lo Stato considera le imprese figure giuridiche da vessare. E non soggetti da proteggere in quanto macchine economiche che producono valore, occupazione e reddito. E forse non a caso la Banca Mondiale ha recentemente emanato la classifica delle nazioni in cui è più facile fare impresa relegando l'Italia al 78° posto nel mondo, dietro il Rwanda! (fonte EconomyRankings Doing Business 2010 Report. Questi erano i miei pensieri, ma ciò nonostante il povero funzionario non aveva poi tutti i torti a lamentarsi di Google visto che continuava a subire i problemi di sempre: le ricerche effettuate con Google producono effettivamente troppo "rumore"!
Google non è un motore di ricerca
Diciamo subito che Google fa quello che deve. Anzi, chi s'intende di IT ogni volta che impiega Google si sbalordisce per il suo straordinario funzionamento. Ma certo non possiamo aspettarci comportamenti miracolosi, tanto più che Google non è un motore di ricerca vero e proprio, ma è un sistema complesso che utilizza i servizi di motore di ricerca per la Internet per raggiungere altri scopi: offrire a chiunque i servizi di SEM, Search Engine Marketing, e farseli ben pagare.
Di fatto i due fondatori di Google, Larry Page e Sergey Brin, hanno costruito un sistema per il SEM intorno a un motore di ricerca per Internet. I motori di Information Retrieval esistevano già da oltre 20 anni, e di motori di ricerca per Internet ce n'erano diversi, e assolutamente potenti (si pensi ad Altavista!). Tuttavia essi sono stati via via messi in ombra poiché Google Search ha incontrato il favore dei milioni di utilizzatori del Web proprio grazie al SEM, sua caratteristica peculiare, e non certo perché Google Search fosse il più potente tra i motori di Information Retrieval.
II due fondatori di Google hanno costruito un sistema per un digital business innovativo che, in maniera completamente unattended, permette a chiunque voglia dare maggiore visibilità al proprio sito Web, di farsi vedere meglio da coloro che effettuano ricerche con Google Search. E grazie a questa peculiarità Google è da considerare senza dubbio la "macchina per far soldi" più efficiente che l'uomo abbia mai inventato! E per questo Google è una tra le compagnie più capitalizzate al mondo.
Larry Page e Sergey Brin sono partiti da un'intuizione geniale. Immaginavano già che il Web sarebbe divenuto un grande network informativo costituito da centinaia di milioni di siti e servizi, costituiti da miliardi di documenti che avrebbero contenuto informazioni simili o addirittura uguali. Erano consapevoli che il ritmo di crescita del numero di pagine, documenti, data base, pubblicati sul Web avrebbe portato di lì a poco al manifestarsi di un fenomeno ben noto nel mondo degli altri media: l'overhead informativo.
I due soci sapevano che potenti calcolatori avrebbero potuto trattare abbastanza facilmente i trilioni di caratteri del Web mediante algoritmi di information retrieval, ma sapevano altrettanto bene che a queste condizioni i risultati della ricerca avrebbero prodotto molto "rumore".
Il loro problema era dunque quello di dare una possibilità alle imprese che avrebbero utilizzato il sito Web per i loro scopi di business, di uscire fuori dal rumore di fondo generato dai motori di ricerca. Immaginavano di offrire loro la possibilità di farsi trovare facilmente, e fare in modo che tutti i navigatori di Internet potessero rintracciare facilmente i loro prodotti e servizi sul Web. Volevano dare alle imprese questa possibilità e ci sono riusciti.
Insomma, Larry Page e Sergey Brin, geni indiscussi dell'IT e del business, sono riusciti a ribaltare in loro favore i nefasti effetti del rumore generato dall'overhead informativo a cui tutti noi siamo oggi sottoposti.
Il problema semantico
Se dovessimo cercare il responsabile del "rumore" dovremmo senza dubbio incolpare il linguaggio naturale.
Il linguaggio naturale viene impiegato dall'uomo da tempo immemorabile, ma solamente da circa 5 mila anni si sono sviluppati linguaggi simbolici per rappresentare conoscenze umane in forma scritta. La scrittura nasce quindi per l'esigenza umana di "congelare" e trasmettere ad altri uomini informazioni. Una volta decifrato il simbolismo, compreso e assimilato il significato, l'informazione scritta si trasforma in conoscenza in colui che legge.
Il Web non è altro che un grande ammasso di documenti elettronici scritti in lingue diverse che contengono conoscenze umane ridotte in informazioni, formalizzate secondo il simbolismo proprio del linguaggio naturale impiegato dall'autore, affinché possano essere lette, decifrate, comprese, assimilate e trasformate in conoscenze da altri uomini.
Anche nel caso di data base, il contenuto delle celle e le etichette che le caratterizzano, è un'informazione generalmente formalizzata secondo un simbolismo proprio di un linguaggio naturale.
Insomma le informazioni contenute nelle pagine Web si trasformano in conoscenze per altri uomini solo nel momento in cui il lettore le comprende e le assimila.
Quando utilizziamo Google per cercare un'informazione di nostro interesse, il calcolatore mette in atto un processo che si conclude in tempi rapidissimi. Direi prodigiosi.
In quella frazione di secondo i potenti algoritmi di text retrieval impiegati da Google Search comparano la stringa che compone la keyword di ricerca con tutte le stringhe contenute in tutti i documenti presenti su Internet. Il motore di ricerca restituisce tutti i documenti che contengono quella stringa.
Poiché nel linguaggio naturale un determinato termine può essere impiegato in diversi contesti, il motore restituisce tutti i documenti che contengono la keyword a prescindere dall'effettivo significato con cui quel termine è stato impiegato. In sostanza il calcolatore non si preoccupa del valore semantico del termine ma solo del suo valore sintattico poiché controlla e paragona una sequenza di caratteri. Ciò comporta che se si stanno per esempio cercando informazioni su una razza canina impiegando la keyword "boxer", il sistema restituirà documenti che parlano di cani, ma anche di motori a scoppio, di motocicli della Piaggio, di mutande da uomo e restituirà perfino documenti contenenti informazioni sul pugilato.
È ovvio che all'aumentare vertiginoso del numero di documenti presenti sul Web questo vincolo tecnologico favorisce la produzione di "rumore".
Ma Google Search è bravissimo. Sulla falsariga di come funzionano quei siti di commercio elettronico, come Amazon o eBay, che propongono automaticamente prodotti in qualche modo correlati a quello che si sta cercando, Goolge Search restituisce anche documenti che contengono termini correlati a quello che viene impiegato come keyword.
Questo è un espediente per cercare di risolvere attraverso l'uso di tecnologie sintattiche, il problema semantico.
La tecnica è semplice e antica, ce l'ha insegnata Aristotele. Si tratta di classificare i concetti e associare ad essi tutti i termini che in qualche modo sono correlati ad essi. Come abbiamo visto, un termine come "boxer" è associabile a più concetti. All'interno di un concetto il termine "boxer" sarà in compagnia di altri termini che si riferiscono a quel concetto. Tecnicamente si parla di creazione di tassonomie in cui i concetti sono rappresentati da termini a cui sono associati tesauri di termini semanticamente omogenei.
Quando viene lanciata una ricerca con una determinata keyword, Google Search andrà a confrontare questo termine con la sua classificazione e lancerà la ricerca anche per altre keyword nascoste.
Questo metodo, studiato per migliorare il ranking, fa sì che documenti contenenti oltre al termine ricercato altri termini appartenenti al tesauro del concetto, vengano inseriti in una posizione più alta nella lista dei risultati.
Ciò permette di dare maggiore "visibilità" a quel documento.
In certe circostanze l'effetto è sorprendente tanto da simulare un comportamento intelligente del computer. Tanto intelligente da far credere che il computer abbia compreso il significato dei termini e i bisogni di colui che effettua la ricerca.
I limiti delle tecnologie per il trattamento del testo
Ma ciò non è vero poiché tutti sanno che il calcolatore è un oggetto molto poco intelligente, capace di eseguire solo qualche decina di operazioni molto elementari. E le tecnologie impiegate per questo scopo sono rigorosamente sintattiche.
Per rendersene conto basta osservare quanto questi meccanismi siano dipendenti dall'alfabeto impiegato ovvero dalla lingua con cui vengono redatti i documenti. Se il calcolatore potesse risolvere davvero il problema semantico, non avrebbe difficoltà a restituire anche documenti redatti in qualsiasi altra lingua ma che contengono informazioni riferite allo stesso argomento.
Per comprendere quanto sia complesso per un calcolatore trattare le lingue naturali basta osservare il funzionamento dei traduttori automatici. Nella migliore delle ipotesi essi effettuano traduzioni a dir poco bizzarre.
Ma allora c'è da domandarsi come mai ci sia ancora qualcuno che affermi con convinzione di possedere tecnologie in grado di trattare la lingua e risolvere il problema semantico.
In realtà non è del tutto falso ciò che taluni affermano.
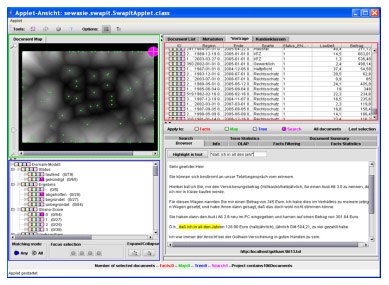
Innanzi tutto chiariamo che esistono diverse classi di tecnologie e metodi di trattamento del testo. Ognuna di esse è nata per affrontare un singolo problema. E proprio per la difficoltà che i calcolatori hanno nel trattare il testo, ognuna di esse viene impiegata in contesti applicativi molto ben definiti.
Per esempio, il Text/Data Mining è un'applicazione particolare del metodo che ho descritto in precedenza per migliorare il ranking. Esso serve proprio a capire quali siano i documenti più pertinenti rispetto agli obiettivi della ricerca, al fine di evitare di leggere un gran numero di documenti solo per capire se sono interessanti o meno. In pratica una tecnologia e applicazioni adatte proprio per gli scopi di quel funzionario statale di cui ho parlato in precedenza. Generalmente l'applicazione analizza con strumenti di text retrieval un documento e confronta tutti i termini contenuti con i tesauri dei vari concetti su cui si concentra la ricerca. Al termine del processo di analisi di tutti i documenti, l'applicazione restituisce una mappa visiva in cui sono raggruppati (cluster) i documenti secondo i vari concetti attribuendogli una valenza semantica del tipo: parlano di "concetto".
Un'applicazione di questo tipo è SWAPit, realizzata dal Fraunhofer-Institut für Angewandte Informationstechnik FIT - di Bonn (Germania), di cui sono disponibili anche diverse demo on-line.
La ricerca ha fatto passi da gigante anche nel campo delle tecnologie NLP, Natural Language Processing. Questa classe di tecnologie offre alle applicazioni informatiche strumenti per l'analisi lessicale, grammaticale, sintattica e semantica del testo al fine di disambiguare le espressioni del linguaggio naturale.
È ovvio che la complessità da gestire è enorme. Basta pensare ai problemi legati al multilinguismo, ossia al trattamento delle strutture linguistiche che contengono parole in diverse lingue; alla disambiguazione del senso delle parole, ossia selezionando il giusto significato delle parole polisemiche a seconda del contesto in cui appaiono; ai termini multi-parola, cioè ad attribuire il giusto senso alle espressioni linguistiche composte da più termini tipicamente utilizzati in ambiti specifici.
Per queste ragioni, si tende a impiegare questa classe di tecnologie in ambiti applicativi circoscritti, affrontando domini di conoscenza rappresentati da lessico ampiamente riconosciuto, al fine di ottenere risultati soddisfacenti.
Un elenco di tools per il Natural Language Processing è disponibile sul sito dell'Università di Charleston.
Text & Data Mining, NLP tools, e altre tecnologie impiegabili per realizzare applicazioni più o meno potenti per trattare il testo, nascondono tuttavia un problema di fondo.
Tutti ci fidiamo degli algoritmi di text retrieval. Se inseriamo una keyword ed effettuiamo una ricerca siamo certi che il documento restituito conterrà quel termine. Poco importa se nel contesto giusto. Sarà poi nella fase di lettura che si potrà decidere se quel testo contiene le informazioni d'interesse.
Ma nel momento in cui è il calcolatore ad attribuire un valore semantico al documento, o a inserire come keyword un termine ripescato nel suo tesauro, chi ci assicura che il calcolatore non commetta errori? Anzi, possiamo esse certi che il calcolatore possa sbagliarsi!
Per questa ragione il risultato ottenuto anche dal più sofisticato e calibrato software non potrà che avere un valore meramente statistico (statistica esplorativa).
Sotto questo punto di vista sarebbe un grave errore sottovalutare questo limite e fidarsi ciecamente delle tecnologie avanzate per il trattamento del testo.
In sostanza sarebbe opportuno non fidarsi troppo di chi afferma di possedere tecnologie "miracolose" in grado di risolvere tutto ciò che la scienza da anni insegue. Ancor peggio se qualcuno ci assicurasse un campo di applicazione ampio e domini di conoscenza illimitati.
Di solito certe organizzazione che offrono servizi di trattamento dell'informazione, nascondono il fatto che la fase di affinamento dei risultati non viene effettuata dal calcolatore in modo automatico, ma bensì questa fase viene effettuata da schiere di persone che pazientemente leggono i testi, li comprendono, acquisiscono l'informazione e decidono se scartarli o meno. Poiché, come già detto, il linguaggio naturale serve per formalizzare conoscenze umane destinate ad altri uomini, e non al calcolatore.
Si cerca ciò che si conosce
Soffermiamoci adesso a riflettere su cosa accade quando si usa un motore di ricerca.
Chiunque di noi ha avvertito grandi vantaggi nella propria vita professionale o personale dal momento in cui è arrivata la larga banda nei nostri uffici e nelle nostre case. Tuttavia il più grande beneficio ci viene proprio da quando abbiamo imparato ad utilizzare Google. È un beneficio tale per cui i nostri posteri, analizzando i fenomeni sociali del passato, inizieranno a considerare un nuovo corso dell'umanità proprio dall'avvento di Google. Io sostengo, con senso di ammirazione per Larry Page e Sergey Brin ma anche con molta ironia, che l'umanità è entrata nell' "Era di Google".
Da quando possiamo utilizzare Google, tutto ci appare a portata di mano. Qualsiasi nostro atto viene guidato da una ricerca su Google, sia che si voglia acquistare un prodotto o che si voglia conoscere come si impiega un certo termine in una lingua straniera. Insomma una vera rivoluzione culturale e sociale.
Tuttavia, anche se tutti sappiamo ormai utilizzare il motore di ricerca con efficacia, tutti abbiamo fatto la brutta esperienza di trovarci di fronte la finestra "Cerca con Google" e non riuscire a digitare nessuna keyword. Perché?
Abbiamo visto che le tecnologie impiegate nei motori di ricerca sono sintattiche e che per effettuare una ricerca è necessario inserire una keyword che rappresenta, in una data lingua naturale, un termine che appartiene a un dominio di parole che ha a che fare con ciò che stiamo cercando.
Ma se non conosciamo niente dell'argomento della ricerca non conosciamo nemmeno nessuna parola che rappresenti quell'argomento. Per tanto non possiamo effettuare la ricerca.
Ed ecco il più grande limite all'uso di queste tecnologie: esse rispondono alla metafora "cerco quello che conosco"!
Il senso di sbigottimento provato davanti alla finestrella di Google è proprio questo: non conoscere ciò che si vuole ricercare, ovvero avere in mente il concetto ma non possedere il lessico per avviare in modo concreto la ricerca.
Di solito però, nei casi di tutti i giorni l'esigenza è quella di scoprire proprio qualcosa che non si conosce. Immaginiamo per esempio un ispettore di polizia che debba già conoscere l'autore del delitto prima di cercarlo. È un paradosso.
Ma vediamo come il nostro ispettore di polizia condurrebbe un'indagine.
Per lui esistono una quantità d'informazione da analizzare che potrebbero costituire indizi, circostanze, fatti, ecc. Ma questi assumono rilevanza per l'indagine solo e solamente se contengono relazioni con il caso. Generalmente le relazioni sono possibili se le informazioni si riferiscono a istanze di "entità" connesse al caso.
Per fare un esempio supponiamo che il delitto si sia consumato in una determinata via di una città, ad una determinata ora di un certo giorno. E che sul luogo ci fosse un testimone e un indiziato a bordo di un'auto in fuga, di cui ovviamente non si conosce l'identità.
Le "entità" che l'ispettore prenderà in esame saranno: città, via, ora, giorno, persona, auto. Ognuna di queste entità avrà nella circostanza una o più istanze. Per esempio la città potrebbe essere Roma, la via Via del Corso, l'ora le 12,00, il giorno il 12 dicembre, la persona testimone potrebbe essere Mario Rossi e l'auto della fuga una Fiat Uno.
È ovvio che l'investigatore andrà alla ricerca tra le informazioni in suo possesso se esistono altre occorrenze delle istanze delle entità prese in esame. Qualora le riscontrasse, l'ispettore potrebbe dedurne che i due fatti potrebbero avere un qualche nesso.
Cercando altre informazioni relative al fatto connesso, potrebbe trovare altre coincidenze o scoprire fatti che collegano altre istanze a quelle già conosciute. E così via.
Insomma l'ispettore di polizia effettua le sue ricerche navigando tra le istanze delle entità di suo interesse al fine di scovare qualche notizia utile ai fini della sua indagine.
Effettivamente questo è un modo molto logico per procedere in una ricerca al fine di trovare qualcosa di cui non si era a conoscenza.
Ma se l'ispettore disponesse di un sistema come Google, potrebbe essere aiutato nella sua ricerca? Purtroppo no. Ma forse, avendo a disposizione un sistema capace di discriminare le "entità" di suo interesse ed estrarre automaticamente le istanze, avrebbe in mano un sistema molto adatto ai propri scopi.
Il calcolatore ci aiuta a conoscere
Tecnologie in grado di fare questo esistono. E sono già disponibili sul mercato sistemi in grado di operare in questo modo. Essi sono comunemente chiamati sistemi per il Knowledge Retrieval.
Questi sistemi non si differenziano molto da semplici motori di ricerca per l'information retrieval, se non per il fatto che sono già predisposti per rilevare le "entità". Ciò avviene grazie all'uso di appropriati algoritmi studiati per rilevare le entità. Ogni entità ha il proprio algoritmo specializzato. Essi possono essere implementati anche grazie all'uso di tecnologie AI (intelligenza artificiale) ed ogni algoritmo è specializzato nel rilevare tutte le istanze di quella particolare entità che sono presenti nei documenti.
Quando un motore di Knowledge Retrieval è in funzione, oltre a cercare le occorrenze delle keyword utilizzate per la ricerca, cerca anche tutte le istanze delle entità predefinite presenti nella collezione documentale recuperata dalla ricerca.
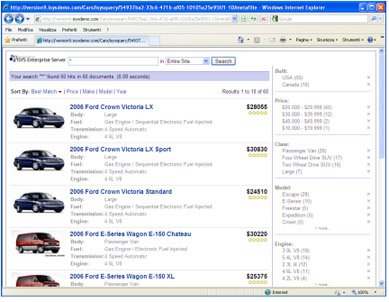
L'interfaccia di un sistema del genere sarà come quella di Google ma presenterà in più le istanze delle entità prescelte in fase di configurazione. Il sistema mostrerà per ogni istanza anche il suo peso, cioè l'indicazione del numero di volte che quell'istanza è presente della collezione documentale recuperata. Ogni istanza è per così dire "attiva" cioè se si clicca su di essa, il motore lancia automaticamente una ricerca e mostra i documenti che contengono quell'istanza.
Il modo di procedere nella ricerca, definita ricerca parametrica, è quindi molto simile al modo di procedere nelle indagini del nostro ispettore di polizia.
Un motore di questo tipo è il celebre ISYS, prodotto da una delle imprese storiche del settore, Isys Search Software. Un esempio di ricerca mediante questo metodo è disponibile qui.
L'esempio è un'applicazione del metodo nel campo delle automobili. Le entità considerate sono: classe, modello, trasmissione, fabbricante e prezzo. Vi consiglio di fare una "prova di guida" del sistema.
Questo approccio alla ricerca full-text è molto interessante poiché non si utilizzano complesse tecnologie per affrontare un problema generale, come nel caso dell'NLP, ma si utilizza il semplice collaudatissimo text retrieval con le tipiche funzioni "semantiche" basate su tassonomie.
Le tecnologie più sofisticate si impiegano solamente per rilevare le entità. Ma poiché ogni entità possiede un numero ridotto di caratteristiche, non è complesso a livello computazionale costruire algoritmi di rilevamento semplici, sicuri e performanti.
Il grande valore di questi sistemi sta quindi nel modo diverso di effettuare le ricerche. Attraverso la ricerca parametrica condotta navigando le "entità", la ricerca torna ad essere naturale. Proprio così come l'ispettore conduce le proprie indagini e noi siamo portati a procedere naturalmente.
Insomma questo metodo tende a superare la metafora "cerco solo ciò che conosco" per arrivare a trovare anche ciò di cui non si era a conoscenza. E in questo caso sarebbe proprio il calcolatore ad aiutarci.
E bello sarebbe se un giorno non troppo lontano anche Google potesse adottare questi metodi e noi tutti potessimo ottenere i benefici offerti dal Knowledge Retrieval.
*Articolo pubblicato sul n. 45 de Il cAos Management
**Luca Severini, è la persona che ha coniato il termine "epistematica". Nel dizionario italiano esiste il termine "epistematico" [deduttivo] impiegato come aggettivo maschile. Il sostantivo femminile "epistematica" è una nuova voce composta dai termini "epistème" [conoscenza] e "informatica" [trattamento automatico dell'informazione],che assume per analogia il significato di "trattamento automatico della conoscenza".
L'Epistematica studia, crea e applica tecnologie che permettono ai calcolatori elettronici di simulare comportamenti intelligenti mediante processi inferenziali effettuati su apposite basi dati arricchite semanticamente, dette basi di conoscenza. Vedi anche su Wikipedia.
Luca Severini è il fondatore della società che prende come denominazione il termine da lui coniato. Epistematica Srl è l'impresa che per prima in Italia si è specializzata nell'applicazione delle tecnologie semantiche per la formalizzazione e il trattamento automatico di conoscenze.
Torna in biblioteca